

ogg how to add header to headless files
The Cat and Mouse Game
I woke up this morning to find that Antoine Vastel had written a third installment in his series on detecting headless Chrome browsers. If you're not familiar with the history here, Antoine has come up with a series of successively more complex techniques to detect headless Chrome for the nominal purpose of blocking web scrapers. All three of his articles have frontpaged on Hacker News, as did my rebuttals to his first two articles which detailed how these techniques can be trivially bypassed and why I consider them user-hostile strategies that invade personal privacy and degrade site performance without actually preventing sophisticated web scraping (see: Making Chrome Headless Undetectable and It is not possible to detect and block Chrome headless). The back and forth has garnered some notable attention, and Paul Irish himself branded it as "Headless Cat and Mouse" and published an npm module with the tests and their corresponding evasions. Granted, he disregarded the code's BSD-2 license, but 🤷♀️.
When I saw Antoine's new post, I couldn't resist the urge to offer up another rebuttal. My main point on this topic has consistently been that there's fundamentally no way to distinguish between automated browsers and real users, and that any attempt at doing so will inevitably result in taking on massive collateral damage in terms of blocking real users and invading the privacy of the users that you don't block. The techniques that are employed for these purposes are extremely invasive, and–quite frankly–a nasty business altogether. For what? At the end of the day, somebody can just run a Windows virtual machine and emulate system-level inputs with the browser if they're really dedicated to bypassing your browser checks.
Many companies gather every piece of information that they possibly can about you and send it up to a remote server for whatever purposes they deem fit. This includes what fonts and plugins you have installed, what your computer hardware is, where you're physically located, what operating system you use, and anything else they can think up. It's already a bit morally dubious whether or not preventing computers from politely interacting with other computers on the internet is a noble pursuit, and it's also no secret that the main use case for browser fingerprinting is tracking users for more nefarious purposes. It's been reported that browser fingerprints can have a 99% success rate in uniquely identifying users… I'm willing to speculate that there's a company or two that views browser fingerprinting as a convenient way to circumvent the GDPR without it being externally detectable. (Editor Note: Evan is not authorized to speak on the behalf of TenantBase, Inc., and–quite frankly–his views are a little extreme for our tastes).
But I digress, let's dig into Antoine's headless Chrome detection approach to see how it works. Then we'll systematically dismantle it. The game must go on…
How the tests work
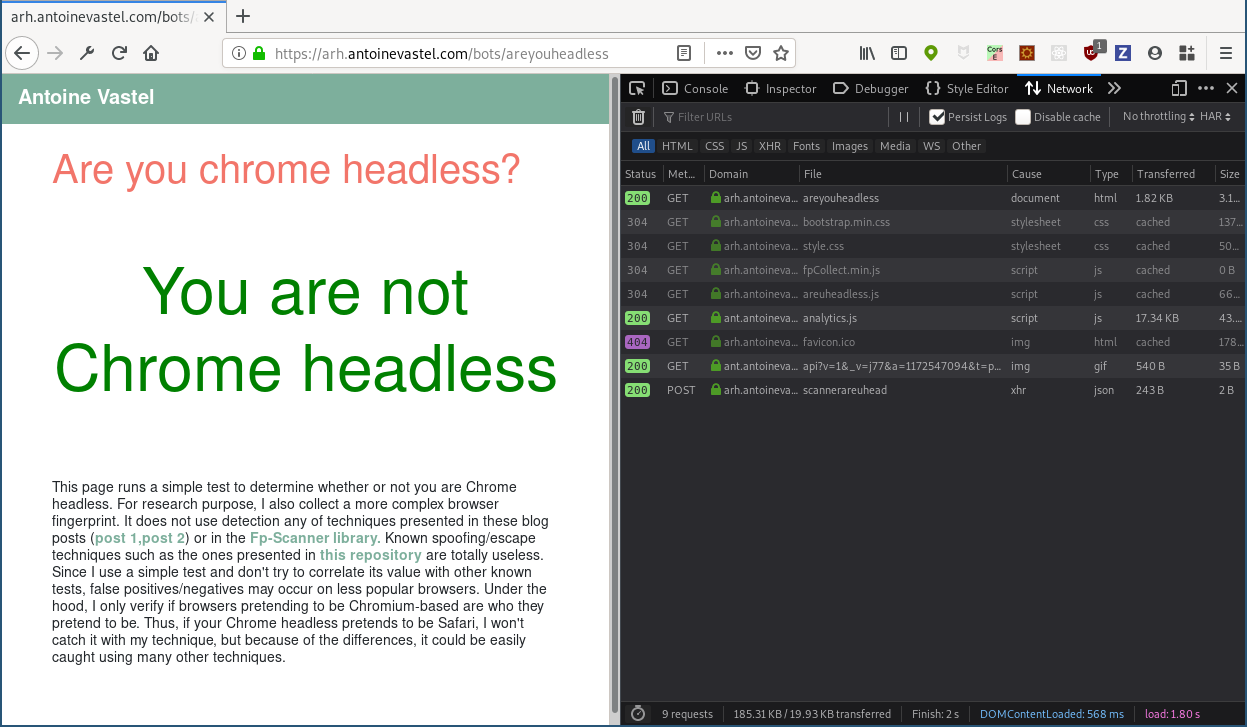
There are a few interesting requests here. In particular, there are three self-hosted JavaScript files called fpCollect.min.js, analytics.js, and areuheadless.js, as well as an XMLHttpRequest (XHR) request to /bots/scannerareuhead. I'm going to go out on a limb here, and suggest that areuheadless.js might have something to do with trying to detect whether or not you're using a headless browser. Let's take a look inside.
document.addEventListener('DOMContentLoaded', function() { (async() => { const fingerprint = await fpCollect.generateFingerprint(); const xhr = new XMLHttpRequest(); // xhr.onreadystatechange = function() { // }; xhr.open('POST', '/bots/scannerareuhead'); xhr.setRequestHeader('Content-Type', 'application/json'); // Don't worry this uuid is not for tracking. A new one is generated at each request. It is to link HTTP headers // and a fingerprint fingerprint.uuid = uuid; fingerprint.url = window.location.href; xhr.send(JSON.stringify(fingerprint)); })(); }); The logic here is pretty simple: it waits for the DOMContentLoaded event, generates an invasive browser fingerprint using Antoine's fp-collect JavaScript library, attaches a UUID to the fingerprint, and then makes a POST request to that /bots/scannerareuhead endpoint that we saw earlier in the Firefox network devtools.
Now let's take a peak at what's being sent up in that request.
{ "plugins": [], "mimeTypes": [], "userAgent": "Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0", "byteLength": "unknown", "gamut": [ false, false, false, false ], "anyPointer": "fine", "anyHover": "hover", "appVersion": "5.0 (X11)", "appName": "Netscape", "appCodeName": "Mozilla", "onLine": true, "cookieEnabled": true, "doNotTrack": true, "hardwareConcurrency": 4, "platform": "Linux x86_64", "oscpu": "Linux x86_64", "timezone": 240, "historyLength": 1, "// .....................................................": true, "// .....................................................": true, "// a bunch of stuff removed for brevity in the blog post": true, "// .....................................................": true, "// .....................................................": true, "videoCodecs": { "ogg": "probably", "h264": "probably", "webm": "probably", "mpeg4v": "", "mpeg4a": "", "theora": "" }, "redPill": 0, "redPill2": null, "redPill3": "200,200,0,200,200,200,200,200,200,400,0,0,200,0,", "uuid": "f2688102-767f-3df0-6215-067b3300fd54", "url": "https://arh.antoinevastel.com/bots/areyouheadless" } I ripped out a bunch of stuff for brevity, but you can see my entire personal fingerprint here. It includes an image rendered using the Canvas API, the computed styling of the body, a dump of the browser's Navigator properties, and all of the usual stuff that you would expect normal websites to collect for totally legitimate reasons. If you want to read more about how browser fingerprints are generated, then I suggest checking out BrowserLeaks.
Bypassing the tests
In the past, I've written extensively about how you can bypass tests like this using general techniques to mock the APIs that fingerprinting libraries use. The code to do that for a test that covers so much of the API gets fairly verbose, so let's approach it from a different angle this time: we'll just skip the whole fingerprinting thing entirely and tell the /bots/areyouheadles endpoint exactly what it wants to hear. That might sound a bit like cheating, but there aren't exactly rules in this game. You can always reverse engineer the fingerprinting techniques used by any website that you're interested in scraping, and many websites with bot-mitigation strategies in place are using commercial services from a small number of vendors that can be bypassed in the same way.
We'll use Google's popular Puppeteer library to control the headless Chrome instance. It provides a simple and powerful API built on top of the Chrome DevTools Protocol, and it's a common choice for both web scraping and UI testing. Here's an example of how we can visit Antoine's test page to check if it is working.
const puppeteer = require('puppeteer'); const performTest = async ( screenshotFilename = 'results.png', ) => { // The URL of the test. const url = 'https://arh.antoinevastel.com/bots/areyouheadless'; // Launch the headless browser and create a new tab. const browser = await puppeteer.launch({ args: ['--no-sandbox', '--disable-setuid-sandbox'], headless: true }); const page = await browser.newPage(); // Visit the page and take a screenshot. await page.goto(url); await page.screenshot({ path: screenshotFilename }); // Clean up the browser before exiting. await browser.close(); }; (async () => { await performTest(); })(); Running this will produce a results.png file with a screenshot of the fully loaded test page.

In order to pass the tests, we just need to use realistic headers in our requests and replace the POST content that gets sent to /bots/scannerareuhead with a consistent fingerprint. The one tricky part is that some of the content in the POST is dynamic–most notably, the UUID and the page URL depend on the specific page that is being visited. It's not clear from the areuheadless.js file exactly where the UUID is coming from, but grepping around reveals that it's embedded into the page in a script tag right below the header.
<script>const uuid = "1ea57ef8-f249-56ef-d684-1b8f2158f64a";</script> This UUID is presumably generated on the backend, injected into rendered pages, and used to match request headers between the fingerprint and the earlier HTML GET request (which will have different headers than the XHR POST (for Accept in particular). Since we're using the fingerprint from my browser, we can just grab the exact same headers (by inspecting them in the network panel). Headers like Host, Referer, Cookie, Connection, Content-Length, and Content-Type are all dynamic and shouldn't be overridden. The only important headers in this case are as follows.
const headers = { 'user-agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0', 'accept-language': 'en-US,en;q=0.5', 'accept-encoding': 'gzip, deflate, br' }; We can just merge these into any request headers from headless Chrome, and everything will be consistent with the recorded fingerprint. We'll need to get the UUID and current URL dynamically from the page, both of which are fortunately quite easy to do with Puppeteer. It's possible to evaluate an arbitrary function in the page context and await the response (and the page.url() method gives us the current URL).
const uuid = await page.evaluate(() => uuid); Pulling this all together, we can use request interception to override the request headers and replace the fingerprint with our prerecorded fingerprint. Assuming that the fingerprint variable has been pre-populated with the fingerprint, we can accomplish this with the following code.
const testUrl = 'https://arh.antoinevastel.com/bots/scannerareuhead'; await page.setRequestInterception(true); page.on('request', async interceptedRequest => { // Merge the header overrides into the request. const headers = { ...interceptedRequest.headers(), ...headerOverrides }; const overrides = { headers }; // Override the fingerprint for the test URL. if (interceptedRequest.url() === testUrl) { // Update the UUID and URL from the page. fingerprint.uuid = await page.evaluate(() => uuid); fingerprint.url = page.url(); // Merge this stuff into the request overrides. const postData = JSON.stringify(fingerprint); overrides.headers['content-length'] = postData.length; overrides.postData = postData; } // Continue on our merry way. interceptedRequest.continue(overrides); }); Embedding that into the test code we ran earlier gives us a final node script that we can run to visit the test page and pass the tests in headless Chrome.
const fs = require('fs'); const puppeteer = require('puppeteer'); const performTest = async ( fingerprintFilename = 'fingerprint.json', screenshotFilename = 'results.png', mockBrowserFingerprint = true ) => { // The URL of the test. const url = 'https://arh.antoinevastel.com/bots/areyouheadless'; // Launch the headless browser and create a new tab. const browser = await puppeteer.launch({ args: ['--no-sandbox', '--disable-setuid-sandbox'], headless: true }); const page = await browser.newPage(); if (mockBrowserFingerprint) { // Load in a prerecorded browser fingerprint. const fingerprint = JSON.parse( fs.readFileSync(fingerprintFilename).toString() ); const testUrl = 'https://arh.antoinevastel.com/bots/scannerareuhead'; const headers = { 'user-agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0', 'accept-language': 'en-US,en;q=0.5', 'accept-encoding': 'gzip, deflate, br' }; await page.setRequestInterception(true); page.on('request', async interceptedRequest => { // Merge the header overrides into the request. const overrides = { headers: { ...interceptedRequest.headers(), ...headers } }; // Override the fingerprint for the test URL. if (interceptedRequest.url() === testUrl) { // Update the UUID and URL from the page. fingerprint.uuid = await page.evaluate(() => uuid); fingerprint.url = page.url(); // Merge this stuff into the request overrides. const postData = JSON.stringify(fingerprint); overrides.headers['content-length'] = postData.length; overrides.postData = postData; } // Continue on our merry way. interceptedRequest.continue(overrides); }); } // Visit the page and take a screenshot. await page.goto(url); await page.screenshot({ path: screenshotFilename }); // Clean up the browser before exiting. await browser.close(); }; (async () => { await performTest(); })(); Running this with node pass-tests.js will produce a second results.png image similar to the following.

And that's all there is to it!
ogg how to add header to headless files
Source: https://www.tenantbase.com/tech/blog/cat-and-mouse/
Posted by: rodriguenother44.blogspot.com
0 Response to "ogg how to add header to headless files"
Post a Comment